Part 3 Post 2: In Post 1, we established the foundation of our Agentic Data Engineer. We abandoned the bloated frontend web frameworks and built an asynchronous, stateful chat UI directly inside a Databricks notebook cell. More importantly, we connected our Agent to the Semantic Layer—giving it background access to Unity Catalog so it can read our enterprise schemas and PII tags before it ever writes a line of code.
But a chat interface that just reads schemas is just a search engine.
Today, we take the leap from chat to execution. We are going to force our Databricks Foundation Model to dynamically write a production-ready Spark Declarative Pipeline (SDP) that not only transforms data but actively secures it.
The Challenge: Distributed Security
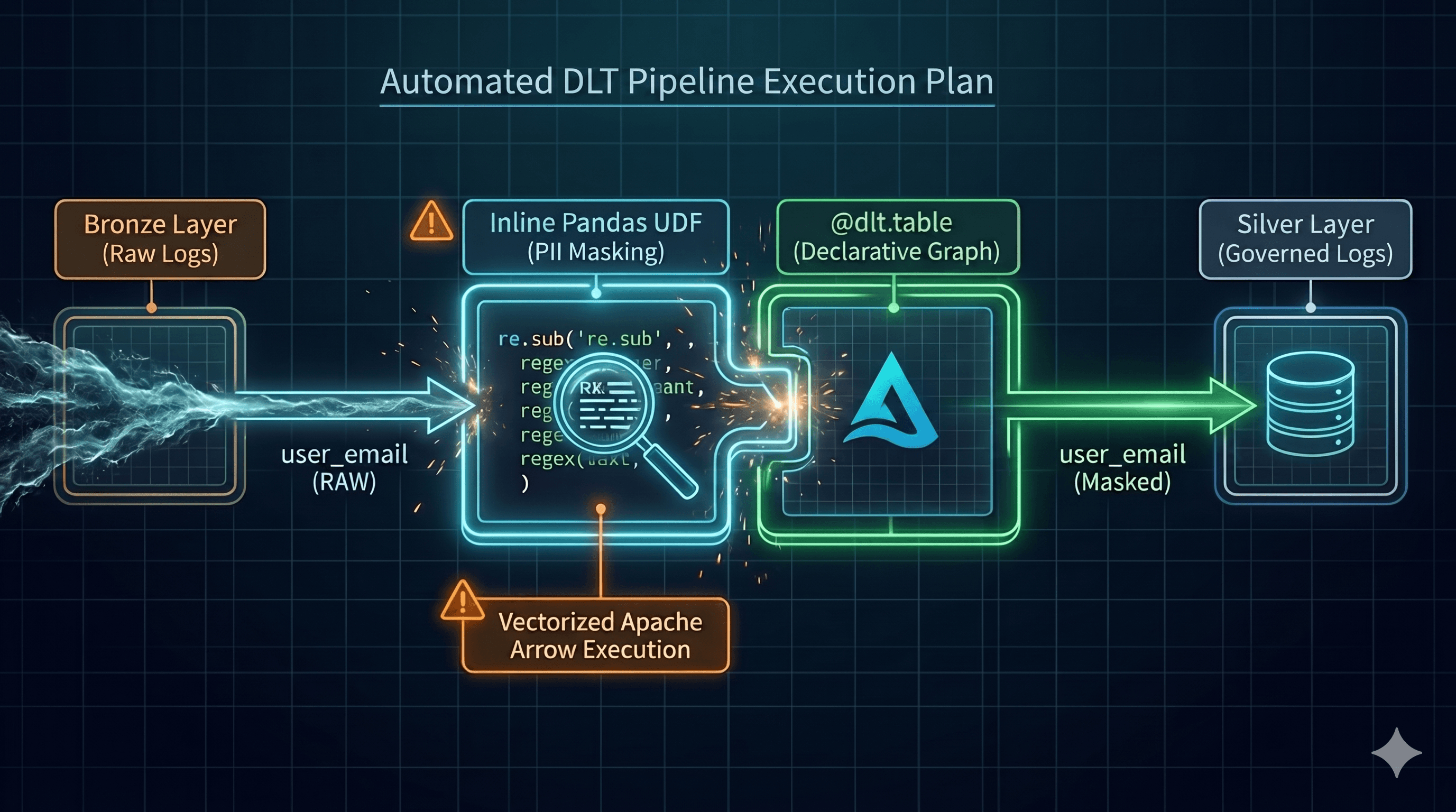
Let’s say our Agent sees that the user_email column in our bronze_logs table is tagged as PII in Unity Catalog. The standard Python developer's instinct is to write a simple re.sub() regex function to mask the emails.
In the enterprise data world, doing that will crash your pipeline.
If you apply a standard Python function to a massive PySpark DataFrame, Spark has to serialize the data row-by-row, sending it back and forth between the Java Virtual Machine (JVM) and the Python runtime. It is a massive performance bottleneck.
To do this correctly at scale, we need the Agent to generate a Pandas UDF (User Defined Function). This allows the regex logic to run in optimized, vectorized batches using Apache Arrow. It is the difference between processing 1,000 rows a second and 100,000 rows a second.
Engineering the Brain: The RCCO Prompt
Generalist AI models like Llama are prone to "drift." If you ask them to write PySpark, they will often default to outdated SparkSession code or generic YAML files.
To force the model to behave like a modern Databricks specialist, we must engineer the System Prompt using the RCCO (Role, Context, Constraints, Output) framework. We inject this directly into our Databricks Workspace Client memory state:
chat_history = [
{
"role": "system",
"content": (
"ROLE: You are an elite Senior Databricks Data Engineer and Security Architect.\n\n"
"CONTEXT: You design automated data pipelines based strictly on Unity Catalog schemas. "
"You must identify columns tagged as PII and mask them before they reach the Silver layer.\n\n"
"CONSTRAINTS: \n"
"1. You must strictly use Databricks Delta Live Tables (DLT) with the `@dlt.table` decorator.\n"
"2. Do NOT just `.drop()` PII columns. You MUST write an inline Pandas UDF (User Defined Function) "
"using the `@pandas_udf` decorator to apply regex masking (e.g., mask emails) to any PII columns.\n"
"3. Do NOT generate standard `SparkSession` code. Do NOT generate Databricks Workflow YAML.\n\n"
"OUTPUT: Return pure, executable PySpark code. Omit conversational filler."
)
}
]The Output: The Self-Securing Pipeline
When we run our notebook cell and ask the Agent to "Create the Silver pipeline for the bronze logs," the RCCO prompt acts as an absolute firewall against bad code.
Because the Agent is semantically aware of the PII tag from Unity Catalog, and structurally constrained by our prompt, it streams this exact, highly-optimized infrastructure back into our notebook:
import dlt
from pyspark.sql.functions import col
from pyspark.sql.functions import pandas_udf
import pandas as pd
import re
# 1. The Inline PII Middleware (Generated autonomously!)
@pandas_udf('string')
def mask_email_udf(email_series: pd.Series) -> pd.Series:
# Vectorized regex masking using Apache Arrow
def mask(email):
if pd.isna(email): return email
# Masks everything before the @ symbol
return re.sub(r'(?<=^.).*(?=@)', '***', str(email))
return email_series.apply(mask)
# 2. The Bronze Ingestion Layer
@dlt.table(
name="bronze_logs_view",
comment="Raw ingestion view"
)
def bronze_logs_view():
return spark.read.table("main.bronze_logs")
# 3. The Secure Silver Pipeline
@dlt.table(
name="silver_logs",
comment="Cleansed logs with PII autonomously masked via Pandas UDF"
)
def silver_logs():
return (
dlt.read("bronze_logs_view")
# Agent dynamically maps the UDF to the column tagged as PII
.withColumn("user_email", mask_email_udf(col("user_email")))
)Look at what just happened. The AI didn't just write code; it acted as a security architect. It identified the vulnerability via metadata and injected vectorized Apache Arrow middleware into a declarative data graph.
📐 The Architect's Note: Code Local, Think Global
In this demonstration, our Agent generated the mask_email_udf directly inside the notebook so you could run it frictionlessly. However, in an enterprise environment, you do not want 50 different pipelines generating their own custom security regex. >
In a mature Databricks Workspace backed by Git integration, you would store this logic centrally. Your Agent's system prompt would simply be instructed to inject: from enterprise_utils.security import mask_email_udf. The AI generates the pipeline, but the enterprise governs the security layer.
The Architectural Reality Check
We have successfully engineered a highly advanced, secure data pipeline. The agent can ingest raw logs, apply vectorized PII masking via Pandas UDFs, and execute a declarative Delta Live Tables graph.
But here is the uncomfortable truth about Generative AI in the enterprise: How do you guarantee the LLM writes it exactly this way, every single time?
How do you prevent a probabilistic model from "helpfully" hallucinating a standard SparkSession instead of a @dlt.table? How do you ensure it doesn't accidentally bypass the masking function when a user phrases their prompt slightly differently?
You cannot build a firewall out of English. Asking a model to "please follow the rules" is a catastrophic single point of failure.
To deploy agentic systems in production, we must strip the model of its creative freedom and bind it to strict, deterministic engineering laws. We have to move from prompt engineering to systems architecture.
Next week, in Part 3, we are locking down the agent. I will be open-sourcing the exact multi-layered architectural standard I use to force compliance: The Structural Execution Framework for Deterministic Task Execution (SEF-DTE).
> Get ready to flip the switch on enterprise governance.