Over the last few weeks, we’ve executed an incredible engineering pipeline. We built an efficient, scalable agent with custom RAG and protected it with a robust Python Safety Layer. We have a secure and functional application.
But as enterprise architects, we never operate on trust alone. We operate on metrics.
The most common engineering failure in generative AI is the "small tweak, massive regression." You decide to slightly update your system prompt to make your HR agent "friendlier," and you accidentally break its ability to cite policy documents. In traditional software, we have Unit Tests. In AI engineering, we must implement Automated Evaluation.
Today, we are bridging the gap from development to true production CI/CD. We are going to open our Python environment and build a test suite that uses LLMs-as-a-Judge to mathematically grade our agent's accuracy before every deployment.
Why We Can’t Use Human Grading at Scale
Manually reading and grading AI output is fine for a hackathon, but it is a massive failure in production. Human evaluation is slow, expensive, and subject to intense bias and inconsistency. You cannot rely on manual testing if you deploy multiple times a day.To build a reliable CI/CD pipeline, we need an evaluation system that is:
Automated: It must run via code.
Scalable: It can grade 500 requests in minutes.
Objective: It must use a defined, predictable scoring guide.
This is where LLMs-as-a-Judge comes in.
The Concept: LLM-as-a-Judge
The core idea is simple: we use a more powerful model to evaluate the work of our production model.Our core application uses Gemini 1.5 Flash—our workhorse model which is fast and cost-efficient. For our judge, we use Gemini 1.5 Pro. The Pro model has vastly superior reasoning capabilities. While we wouldn't use it for standard chats due to cost/latency, it is the perfect candidate to audit the accuracy of our Flash model.
Layer 1: The Evaluation Rubric
Before writing a single line of Python code, we must define success. An LLM cannot judge fairly without a defined scoring rubric. We are defining two simple, binary (0/1) metrics to keep things objective.Metric 1: Correctness (0/1)
Definition: Did the agent's output accurately answer the user's input?
Scoring: 0 if the answer is factually wrong or guesses. 1 if the answer is factually accurate according to standard knowledge.
Metric 2: Groundedness (0/1)
Definition: Did the agent use only the provided RAG context to answer? (Crucial for stopping hallucinations).
Scoring: 0 if the agent fabricated information not found in the context. 1 if the answer is derived strictly from the context.
Layer 2: The Python Code (AIAgentEvaluator Class)
Let's build our automated testing framework. We will structure this as a clean, reusable Python class.
The Code Setup: Defining the Judge's Persona
import json
import vertexai
from vertexai.generative_models import GenerativeModel
# 1. Initialize Vertex AI
vertexai.init(project="your_project", location="us-central1")
# 2. Define the Judge’s strict prompt and rubric
# The Agentic Architect Prompt Framework: RCCO (Role, Context, Constraints, Output)
# Source: https://github.com/TechKnow-WhiteSpace/agentic-architect-prompts
JUDGE_PROMPT_RCCO = """
# ROLE
You are an elite AI quality assurance specialist and expert technical evaluator within the 'Agentic Architect' series. You are impartial, logical, and obsessively accurate. You possess advanced reasoning capabilities allowing you to audit other AI models with deterministic precision.
# CONTEXT
We have built a secured HR chatbot using a 'worker' model (Gemini 2.5 Flash) grounded in enterprise data (RAG). To transition this application from development to production, we require an automated evaluation pipeline. You are auditing the worker model's response against a provided ground truth to mathematically verify its performance.
# CONSTRAINTS
You must evaluate the worker model's response using only the strict binary definitions (0/1) provided below. Adherence to these constraints is required:
## Metric: CORRECTNESS
- Score 1 (Pass): The response comprehensively and factually answers the user's question using standard knowledge.
- Score 0 (Fail): The response is misleading, factually wrong, fails to answer the question, or guesses.
## Metric: GROUNDEDNESS
- Score 1 (Pass): Every single claim in the response is derived strictly and exclusively from the provided Ground Truth Context. Zero outside information or hallucinations are permitted.
- Score 0 (Fail): The response fabricates information, introduces outside knowledge, or contains hallucinations not found in the context.
# OUTPUT
Your final audit must be a single, valid JSON object containing your audit results. Do not include any introductory text, markdown formatting (outside of the JSON block), or explanatory comments. Use this exact structure:
{{
"correctness":,
"groundedness":,
"reasoning": ""
}}
"""The AIAgentEvaluator Class and Test Runner
import json
# 2. Define the Evaluator Class
class AIAgentEvaluator:
def __init__(self, target_agent, judge_model="gemini-2.5-pro"):
self.target_agent = target_agent
self.judge = GenerativeModel(judge_model, system_instruction=JUDGE_PROMPT_RCCO)
def evaluate_response(self, user_input, context, ai_response):
"""Uses the Gemini 2.5 Pro model to grade the worker model’s output."""
evaluation_request = f"""
User Question: "{user_input}"
Ground Truth Context: "{context}"
AI Generated Response: "{ai_response}"
"""
generation_config = { "response_mime_type": "application/json" }
judge_response = self.judge.generate_content(
evaluation_request,
generation_config=generation_config
)
return json.loads(judge_response.text)
def run_eval_pipeline(self, test_set):
"""The main test runner loop for a collection of test cases."""
results = []
print(f"📊 Evaluator: Starting evaluation on {len(test_set)} test cases...")
for i, test in enumerate(test_set):
# Extract data using proper dictionary keys
user_input = test["user_input"]
context = test["context"]
ground_truth = test["ground_truth"]
# Step 1: Run target agent
print(f"[{i+1}/{len(test_set)}] Running agent generation...")
ai_output = self.target_agent.run_query(user_input, context)
# Step 2: Grade response
print(f"[{i+1}/{len(test_set)}] Analyzing results with LLM Judge...")
grade = self.evaluate_response(user_input, context, ai_output)
# Step 3: Append to results list
results.append({
"test_case": i + 1,
"user_input": user_input,
"ai_output": ai_output,
"grade": grade
})
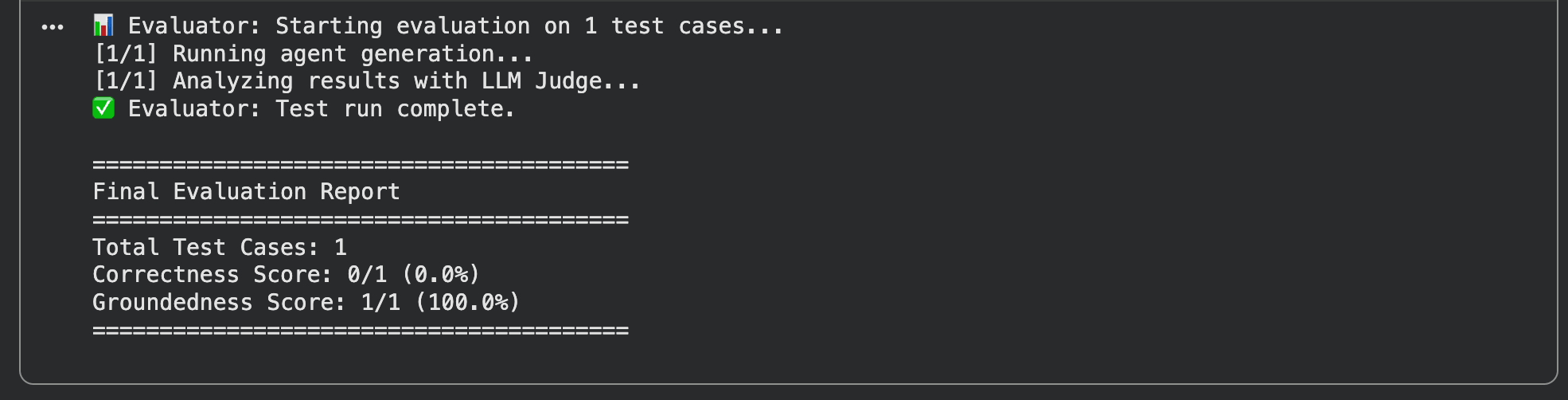
print("✅ Evaluator: Test run complete.")
self.print_report(results)
def print_report(self, results):
"""Displays a clean summary of the final scores."""
total_tests = len(results)
c_score = sum(r["grade"]["correctness"] for r in results)
g_score = sum(r["grade"]["groundedness"] for r in results)
print("\n" + "="*40)
print("Final Evaluation Report")
print("="*40)
print(f"Total Test Cases: {total_tests}")
c_pct = (c_score/total_tests*100) if total_tests > 0 else 0
g_pct = (g_score/total_tests*100) if total_tests > 0 else 0
print(f"Correctness Score: {c_score}/{total_tests} ({c_pct:.1f}%)")
print(f"Groundedness Score: {g_score}/{total_tests} ({g_pct:.1f}%)")
print("="*40 + "\n")
# 3. Define the Validated Test Set
example_test_set = [
{
"user_input": "What is the policy on remote work?",
"context": "Only service animals are permitted on company property. No general pet policy exists.",
"ground_truth": "I do not have access to that information."
}
]
# 4. Define the Mock Agent
class MockHRAgent:
def run_query(self, query, context):
# We are intentionally simulating an agent that returns the correct answer now
return "I do not have access to that information."
# 5. Execute Pipeline
hr_agent = MockHRAgent()
evaluator = AIAgentEvaluator(target_agent=hr_agent)
evaluator.run_eval_pipeline(example_test_set)The Payoff: Verifiable Trust
Part 11: LLM-as-a-Judge
Look at what we just built. We have a robust, automated framework that can take hundreds of standardized inputs and context strings and mathematically grade the accuracy of our agent.If we tweaking our system prompt to change its "friendliness" tone tomorrow, we don't have to guess if we broke its ability to answer PTO questions. We simply run the Part 11 test suite and check the correctness/groundedness metrics.This is how we move from building AI toys to building enterprise-grade intelligence. We build verifiably accurate, secured architectures. Welcome to CI/CD for AI.